Gaussian Smoothing¶
This simple case shows how to run the function of Gaussian smoothing in Stereopy. Gaussian smoothing can make expression matrix closer to reality [Shen22].
Generally, preprocessing, including quality control, filtering and normalization, and PCA should be done before running Gaussian smoothing. Meanwhile, you also have to save raw expression matrix by data.tl.raw_checkpoint before the operations which will change the expression matrix.
Observation on genes¶
Here to download our example data.
[1]:
import stereo as st
import warnings
warnings.filterwarnings('ignore')
# read data
input_file = './SS200000141TL_B5_raw.h5ad'
data = st.io.read_h5ad(input_file, spatial_key='spatial')
# preprocessing
data.tl.cal_qc()
data.tl.filter_cells(min_counts=300, pct_counts_mt=10)
data.tl.filter_genes(min_cells=10)
# save raw data
data.tl.raw_checkpoint()
data.tl.normalize_total(target_sum=10000)
data.tl.log1p()
# PCA
data.tl.pca(use_highly_genes=False, n_pcs=50, svd_solver='arpack')
# Gaussian smoothing
data.tl.gaussian_smooth(n_neighbors=10, smooth_threshold=90)
data.tl.scale(max_value=10) # only for gaussian_smooth_scatter_by_gene
# plot
data.plt.gaussian_smooth_scatter_by_gene(gene_name='C1ql2')
data.plt.gaussian_smooth_scatter_by_gene(gene_name='Irx2')
data.plt.gaussian_smooth_scatter_by_gene(gene_name='Calb1')


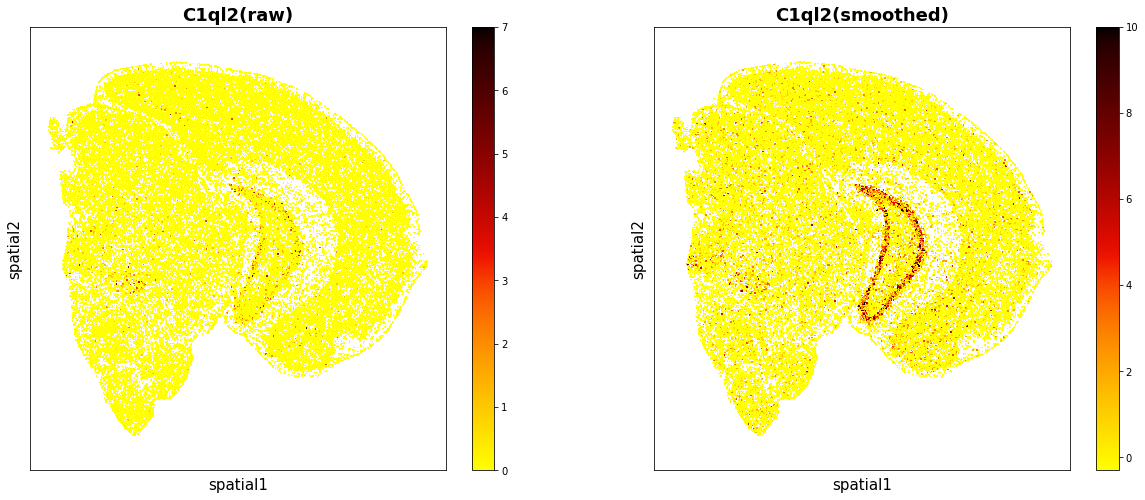

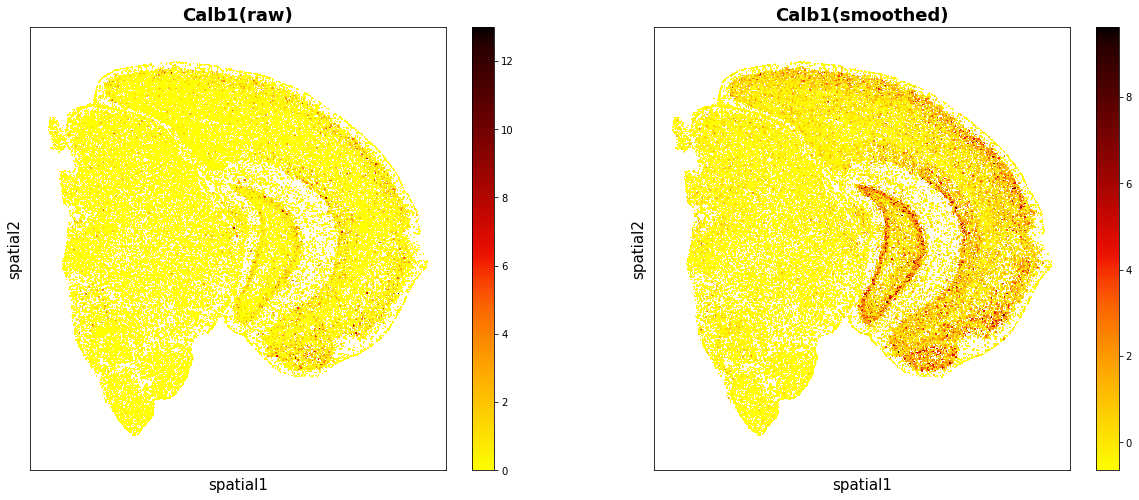
Obervation on clusters¶
Whereafter, if you want to do other operations such as clustering, the same processing steps should have been done.
[2]:
import stereo as st
import os
import warnings
warnings.filterwarnings('ignore')
# read data
input_file = './SS200000141TL_B5_raw.h5ad'
data = st.io.read_ann_h5ad(input_file, spatial_key='spatial')
# preprocessing
data.tl.cal_qc()
data.tl.filter_cells(min_counts=300, pct_counts_mt=10)
data.tl.filter_genes(min_cells=10)
data.tl.raw_checkpoint() # save raw data
data.tl.normalize_total(target_sum=10000)
data.tl.log1p()
# PCA
data.tl.pca(use_highly_genes=False, n_pcs=50, svd_solver='arpack')
# Gaussian smoothing
data.tl.gaussian_smooth(n_neighbors=10, smooth_threshold=90)
data.tl.normalize_total(target_sum=10000)
data.tl.log1p()
# clustering
data.tl.pca(use_highly_genes=False, n_pcs=50, svd_solver='arpack')
data.tl.neighbors(pca_res_key='pca', n_pcs=30, res_key='neighbors')
data.tl.leiden(neighbors_res_key='neighbors', res_key='leiden')
data.plt.cluster_scatter(res_key='leiden')
[2]:
<AxesSubplot:>

Gaussian smoothing is able to make the clustering result to more subtypes as below:
Performance¶
The example data contains 61857 cells (bins) and 24562 genes.
Machine configuration as below:
physical cores |
logic cores |
memory |
|---|---|---|
12 |
48 |
250G |
This module only supports single process.
process |
memory(max) |
cpu |
time |
|---|---|---|---|
1 |
8.5G |
2736% |
1.8m |